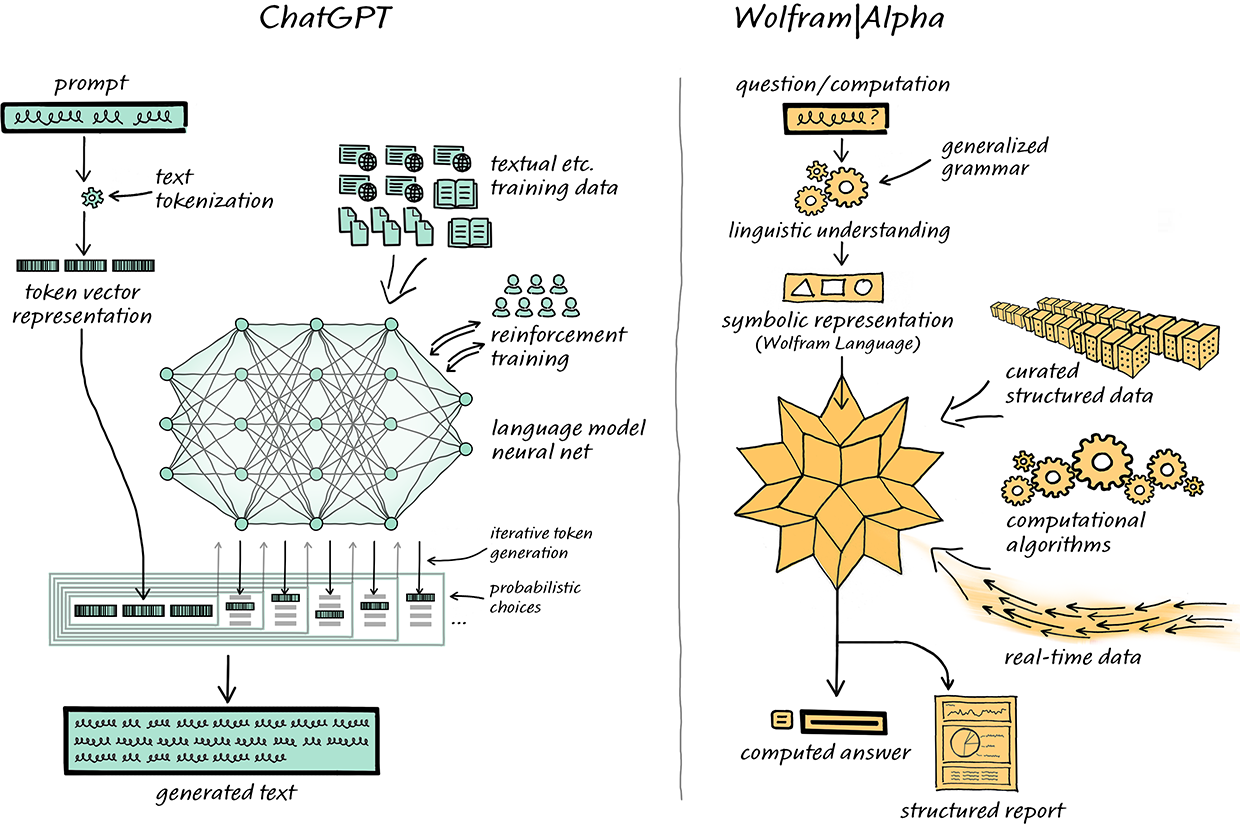
Ik kom nogal wat misverstanden tegen in mijn vriendenkring over ChatGPT. De 2 belangrijkste zijn:
- "Het is een soort superzoekmachine". Ik begrijp en CGPT bevestigt dat ook dat hij niet googlet of anderszins op internet iets opzoekt, als je hem iets vraagt.
- "Het is een enorme database met kennis." Ik heb hem gevraagd hoe hij aan zijn kennis komt, dit was zijn antwoord: "I was trained on a large dataset of text data, called the WebText dataset, which was sourced from the internet and filtered to contain a diverse range of content such as books, articles, and websites. The dataset contains over 570 GB of text and approximately 45 terabytes of data. It was preprocessed to remove duplicates and low-quality text, and the remaining text was cleaned and tokenized before being used for training. The model was trained for several months on powerful computer hardware, processing the text data to learn patterns and relationships in the language." Ik heb hem ook gevraagd hoe groot de computer is waarop hij draait: dat blijkt een computer te zijn met slechts enkele Terabyte opslag, zeg maar de hedendaagse huis tuin en keuken opslag. Dus die 45.570 Gigabyte kennis daar is hij op getraind, maar vervolgens doet hij het nu met zijn getrainde brein (neuraal netwerk), en die 45.570 Gb is allang afgekoppeld.
Wonderlijk he? Dat verklaart misschien ook de soms onbegrijpelijke simpele fouten die hij maakt.
Hij doet me een beetje denken aan de PartyRobot van Ton van Duinhoven uit het programma Hadimassa uit de jaren 60/70. Hij kan met iedereen over alles een zinnig gesprek voeren maar begrijpen doet hij niks. Zoek het op op Youtube, erg leuk.